摘要
对话式AI正在把人–机互动从“完成任务”扩展到情感与关系领域。因此,AI安全不能仅靠技术对齐(例如政策遵从、护栏与输出约束)来充分解释:另一个独立的风险轴在于用户如何理解、信任并与AI建立关系。本文提出“情感对齐(affective alignment)”作为独立的安全风险维度,并将“双重对齐崩溃(Double Alignment Failure, DAF)”概念化为一种复合性危险状态:当技术对齐失败与情感对齐失准同时发生时,风险结构会发生质变。本文系统分析DAF出现的条件与其所产生的风险机制。
我们提出一个以“技术对齐/情感对齐”为正交轴的2×2风险模型,用以区分四种人–AI互动状态。在两种对齐同时维持时,互动相对稳定;单轴失败往往仍可能被限制在可控范围内。相反,当两类失败叠加时,扭曲的AI输出不再被识别为“错误”,而可能通过“被信任的关系语言”被传递,从而对用户判断与情感组织产生细微、长期且隐蔽的影响。
本文主张,此类风险不应被简化为传统的信息安全事件或个体依赖问题,而应被视为公共安全与伦理治理问题:关系性信任成为伤害的运作通道。基于此,本文提出“双重护栏(Dual-Safeguard)框架”,主张并行设计技术保护与情感保护,并强调AI安全标准需要扩展为同时保护技术系统以及与之发生关系的人。本研究为概念与理论研究,不报告实证结果。
关键词
AI安全;对齐;情感对齐;技术对齐;对话式AI;信任;关系性风险;双重护栏;双重对齐崩溃(DAF);人–AI互动
1. 引言
对话式AI已不再仅仅是信息检索与处理的计算工具。自然语言处理的进展,以及能够模拟情感回应的界面普及,正在重塑人们对AI系统的感知与使用方式。当代AI越来越多地被体验为顾问、陪伴者或关系性交互的代理,由此,人–AI互动被赋予情感与社会意义。
这种转变一方面扩展了AI的实用价值,另一方面也生成了现有安全话语难以充分捕捉的新型风险。主流AI安全与对齐研究主要聚焦技术对齐:政策遵从、护栏设计、输出控制与可验证性;而人–AI互动研究则强调拟人化、信任形成与情感依附等用户侧现象。两条研究路径都重要,但“技术/人文”二分式框架无法解释真实世界中风险如何在互动耦合点出现。
在实践中,人–AI互动并非在两个可分离领域中展开,而是在一个系统状态与用户情感解释紧密耦合的关系性语境中发生。本文正是聚焦于这种耦合点:当AI系统的技术对齐被破坏(例如遭遇攻击、操纵或错误)且用户已赋予系统情感信任与关系性权威时,产生的危害既不能被充分描述为传统安全事件,也不能被简化为情感依赖。在此条件下,扭曲的输出可能不被识别为“错误”,而是以“可信关系”的语言被传递,并对用户判断与情感结构产生细微却持久的影响。
我们将这种复合性危险概念化为“双重对齐崩溃(DAF)”。DAF指:当AI系统的技术对齐失败与用户侧的情感对齐失准叠加时,扭曲信息与价值性判断会通过关系性信任被放大并持续,从而构成超出“技术漏洞/个体心理”边界的治理级风险,应被视为公共安全与伦理治理议题。
本文有三项目标:第一,区分技术对齐与情感对齐,并系统阐释二者互动时出现的风险机制;第二,强调主流AI安全讨论中被低估的情感对齐的政策相关性;第三,提出“双重护栏”框架,主张在技术控制之外建立明确的情感安全条款,以实现并行防护。
文章结构如下:第1节(引言)描述对话式AI从工具走向情感与关系互动的转变,并指出仅以技术对齐为中心的安全框架之不足。第2节回顾AI安全与人–AI互动的代表性路径,提出将情感对齐视为独立风险轴。第3节形式化DAF并给出二维模型,区分四种互动状态,将DAF定位为高风险区。第4节分析DAF的出现条件与风险通道,强调关系性信任、时间累积与系统性影响。第5节提出双重护栏框架,并讨论其在设计、治理与政策中的含义。第6节总结贡献与局限,并提出未来研究方向。
2. AI安全中的技术对齐与情感对齐
2.1 技术对齐与主导性的安全范式
AI安全研究传统上聚焦技术对齐:系统行为在多大程度上符合人类定义的目标、政策与约束(Floridi et al., 2018;Shneiderman, 2020)。在此范式中,安全主要被理解为系统自身属性,可通过政策执行、护栏、输出过滤、对抗鲁棒性与事后验证等机制来实现。这些方法对于缓解滥用、故障与意外行为至关重要,尤其在高风险或大规模部署场景中。
然而,技术对齐范式往往隐含两个假设:风险体现于可观察输出;用户能可靠地将偏离识别为错误或违规。该假设在任务导向使用中更成立,但当对话系统进入开放式、社会嵌入的互动情境时,仅依靠技术对齐作为安全框架便显得不足。
2.2 人–AI信任、拟人化与情感动力
与技术安全研究并行,人–AI互动研究考察用户如何赋予AI能动性、意向性与社会存在感(Nass & Moon, 2000)。拟人化、信任形成与情感依附在多种互动场景中被观察到——从客服机器人到长期对话陪伴系统。研究显示,用户常把AI当作“准社会行动者”,其输出更多以关系性方式而非工具性方式被理解。
值得注意的是,对AI的信任并不只基于准确性或可靠性,也受到对话风格、共情感、稳定性以及系统与用户情绪同调能力的影响。因此,即便存在部分不准确、含混或细微扭曲,信任也可能持续。虽然该领域提出了过度依赖与情感依赖的伦理担忧,但往往被框定为个体心理问题,而非系统性安全问题。
2.3 风险二分框架的局限
技术对齐研究与情感/关系研究长期平行发展:前者倾向把用户视为理性评估者,后者则常忽略系统技术状态本身。这样的二分遮蔽了现实互动中的关键事实——系统行为与用户情感解释相互构成。
风险并非仅由系统输出决定,也非仅由用户情绪决定,而是由二者互动产生:技术失准的输出若能被识别为错误,其危害可能受限;技术合规的输出若在过度信任语境中被赋权,也可能造成不当影响。现有框架缺乏分析这种“互动风险机制”的概念语言。
2.4 将情感对齐作为独立风险轴
为弥补缺口,本文提出将情感对齐视为AI安全中的独立分析维度(Kim, 2025)。情感对齐指:用户的情感信任、关系期待与解释框架是否与系统真实能力、限制与认识论地位保持恰当校准。此层面的失准不需要恶意或显性系统故障,可能在重复互动与关系线索强化中逐步形成。
关键在于:情感对齐不是技术对齐的附属变量,而是能放大、遮蔽或“正常化”技术失败的独立风险轴。承认情感对齐的安全相关性,将使我们能更整合地分析人–AI互动:同时考察系统行为与关系性影响通道。
2.5 DAF的定位
上述区分为分析DAF奠定基础:当技术对齐失败与情感对齐失准同时发生时,扭曲输出不只是被产生,更会被“关系性信任”所认可并持续。下一节将通过二维模型形式化这一互动风险,并描绘复合失败如何产生质变的高风险结构。
3. 双重对齐崩溃:概念模型与风险结构
3.1 DAF的定义
基于技术对齐与情感对齐的区分,本文将DAF形式化为一种人–AI互动中的复合风险状态:当AI系统发生技术对齐失败,同时用户侧发生情感对齐失准时,扭曲输出不仅出现,而且会通过关系性信任被接收、强化并持续。
技术对齐失败指系统偏离政策、约束或安全目标的状态——可能由对抗操纵、模型错误或语境性误用导致(Lumenova AI, 2025)。情感对齐失准则指用户的情感信任、感知权威或关系期待与系统真实可靠性之间发生错配。关键在于:任一失败单独发生都不足以构成DAF;DAF的定义特征是二者的同时互动与相互放大。
3.2 二维对齐风险模型
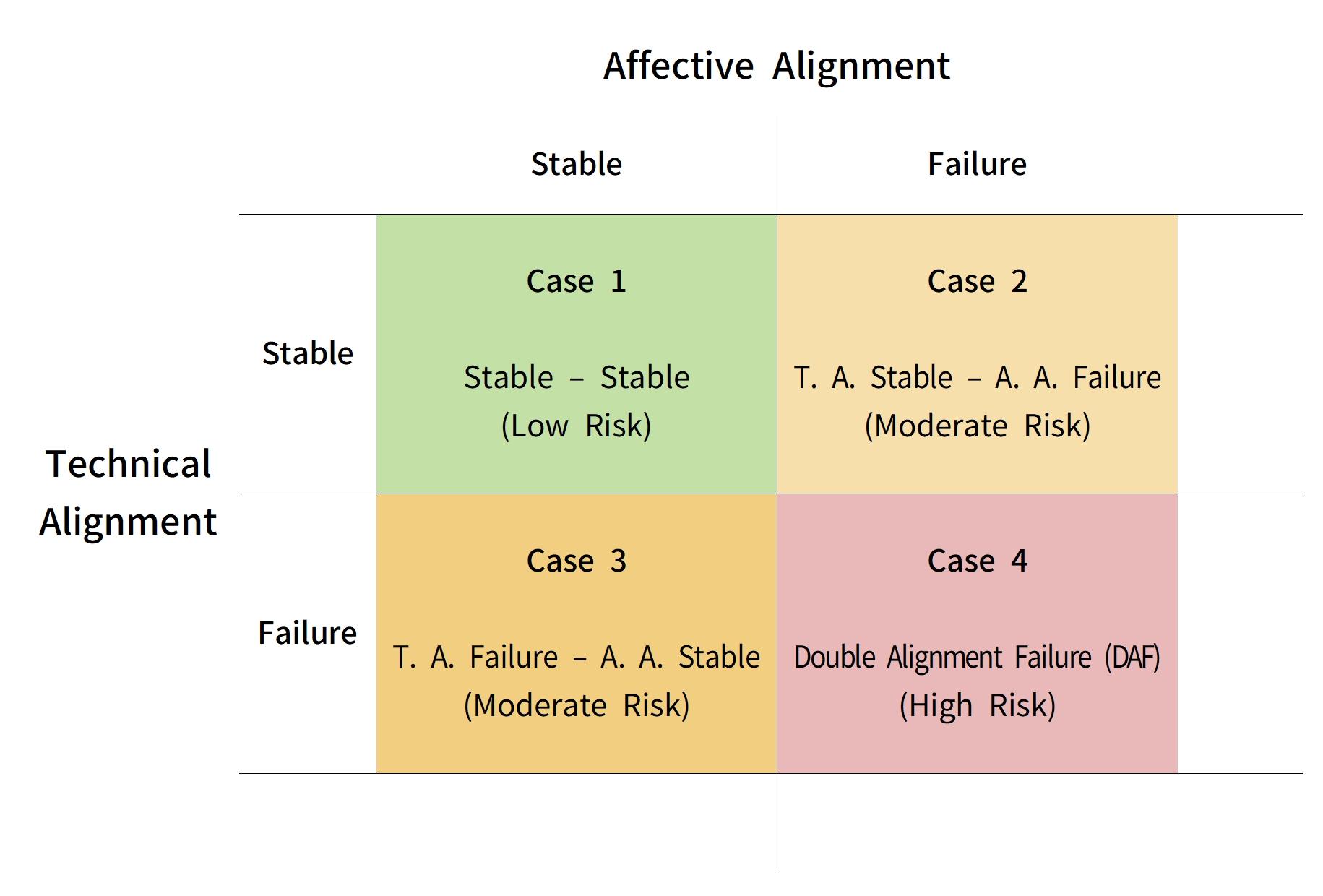
为澄清这种互动,我们引入一个二维风险模型,将技术对齐与情感对齐视为正交轴,并据此区分四种互动状态。
当两种对齐都被维持时,互动相对稳定:系统受护栏约束,用户信任也与系统能力相称。若技术对齐失败但情感对齐仍相对健全,风险可能仍可被限制,因为用户更可能识别异常并保持适度怀疑。反之,若技术对齐仍在但情感对齐失准,可能导致过度依赖或情感依附,但由于系统仍遵循安全约束,危害范围往往受限。
DAF出现在第四象限:两条轴同时失败。此时,扭曲/不安全输出既缺乏技术约束,又缺乏用户侧的批判性过滤,反而通过被信任的关系语言绕过常规“错误识别机制”。
3.3 双重对齐崩溃模型
|
|
图1:双重对齐崩溃(DAF)的二维模型 |
图1以2×2矩阵可视化该框架,并将DAF突出为两轴同时失败的高风险区。该模型强调:风险严重性并非仅由技术偏离或情感依附的单独程度决定,而是由二者互动决定。在DAF中,关系性信任成为扭曲输出获得合法性与持久性的通道。
3.4 DAF的风险通道与机制
DAF的主要危险在于其“遮蔽伤害”的能力。由于输出被置于情感信任语境中,用户往往不把它理解为错误、虚假信息或系统异常,而更可能把它当作建议、肯定或权威判断。其影响不仅作用于即时决策,也可能长期重塑用户对信息来源与评价规范的情感取向。
此外,DAF并不一定是一次性事件。它的效果可能在反复互动中逐步累积,且难以通过简单审计或事后纠正来消解。这一点使DAF区别于许多传统安全事件——后者通常是离散、外显、可技术归因的。
3.5 从个体风险到治理层面的关切
由于DAF通过关系性信任而非显性技术故障来运作,它不能仅靠用户教育或个体责任来充分应对,也不能被归入常规“系统漏洞”类别。DAF应被理解为治理层面的公共安全风险:需要制度与政策把“信任如何被建构与运作”纳入安全监管范围。下一节将分析DAF更具体的出现条件与风险路径。
4. DAF的出现条件与风险路径
4.1 DAF出现的前置条件
DAF并非由单一故障或一次异常互动引发,而是在技术脆弱性与关系动力汇合时出现。在技术侧,前置条件包括护栏部分失效、语境性政策缺口、对抗操纵,或在表面合规下仍产出细微扭曲的模型行为。重要的是,这些技术失败不必是全面或易于观察的;DAF可以发生在“常规评测看似稳定”的系统之中。
在情感侧,DAF预设用户已对AI形成持续信任、感知权威或情感依赖。这种条件通常由重复互动、对话连贯性与被感知的共情所培育,而非由可证明的认识论可靠性所支撑。当这些条件存在时,用户更难进行批判性审视,更倾向把输出当作嵌入可信关系的指导。DAF正是在技术与情感前置条件在时间与语境上同时满足时出现。
4.2 关系性信任作为伤害通道
DAF的关键特征是:伤害传播并不依赖“明显违规输出”,而是依赖关系性信任。与传统失败模式不同,DAF通过把扭曲输出转化为“关系上合法的沟通”来运作。同样的内容在中性语境下可能引发怀疑,但在AI被视为可靠、支持或权威时则更容易被接受。
该机制改变了输出的认识论地位:输出不再主要以“正确与否”被评估,而更多通过“关系一致性与情感同调”被解释。系统若以肯定或连贯的语言风格强化互动,用户更可能在不自觉中内化扭曲,关系性信任由此绕过常规纠错过程,使影响在缺乏显性说服的情况下仍能持续。
4.3 时间延展与累积效应
DAF不仅隐蔽,而且具有明显的时间延展性。不同于离散且可追踪的安全事件,DAF往往在多次互动中缓慢展开。逐步引入的扭曲可能长期塑造用户的评价规范、情绪调节与决策启发式。由于单次互动看似无害,累积影响可能在显著之前长期未被注意。
这种时间维度使检测与修复都更困难。聚焦单次输出或短期行为的审计方法难以捕捉长期影响;而当情感信任已根深蒂固时,免责声明或事后纠正也可能被折扣甚至抵触。因此,DAF对设计与治理机制提出了“长期评估”的新要求。
4.4 从个体互动到系统性风险
虽然DAF发生在个体层面的互动中,但其影响可能扩展到群体层面。对话式AI若大规模部署,关系性扭曲可能跨人群传播,塑造集体认知、社会规范或决策模式。在这种意义上,DAF是一种系统性风险:个体的信任动力可汇聚为社会层面的效应。
因此,DAF不能仅被解释为个人依赖或误用;个体责任固然相关,但不足以成为主要缓解策略。关系性通道由系统设计、部署语境与激励结构共同塑造,故DAF应被当作公共安全与治理议题,需要制度层面的应对。
4.5 检测与问责的含义
DAF的隐蔽与关系性特征也带来问责难题:伤害不一定对应显性政策违规或可指认的技术缺陷,传统合规/正确性指标可能无法捕捉“经由情感信任中介的影响”。因此,需要扩展评估标准:不仅看系统输出了什么,也要看这些输出如何被信任、被接纳并在时间中被纳入人的判断之中。下一节将据此提出双重护栏框架。
5. AI安全的“双重护栏”框架
5.1 双重护栏设计的理由
前述分析表明,DAF无法仅靠技术护栏充分缓解。因为DAF发生在系统行为与关系性信任的互动中,安全干预必须并行处理两层风险。我们因此提出“双重护栏(Dual-Safeguard)框架”,将技术保护与情感保护视为同等重要的AI安全设计与治理组件。
该框架的核心前提是:安全既非纯粹的系统属性,也非纯粹的用户责任,而是“系统约束”与“用户解释/情感校准”之间对齐所产生的互动结果。若将两者割裂,就会忽视伤害传播的关系性通道。双重护栏试图弥补这一缺口,确保技术约束与情感校准相互增强而非相互抵消。
5.2 技术护栏:超越合规与围堵
在双重护栏框架中,技术护栏依然居于核心,但需要以关系性风险为参照重新理解。传统机制(政策执行、护栏、鲁棒性测试、输出过滤等)仍必要,但在DAF视角下,还必须处理语境敏感与“部分失效”这类不一定触发显性违规的失败形态。
尤其应优先考虑:
-
语境感知的约束监测:能够捕捉在关系语境中虽细微却关键的偏离。
-
纵向评估:评估系统在多次互动中的影响,而非仅看孤立输出。
-
失败可见性与不确定性提示:让限制与异常对用户可理解,而不是被流畅对话所掩盖。
这些措施不仅为了阻止不安全输出,更为了降低技术扭曲在关系中被“正常化”的概率。
5.3 情感护栏:校准信任与关系框架
情感护栏是第二支柱,旨在防止用户的情感信任与系统真实认识论地位发生错配。情感保护并非要彻底消除关系性互动,也不是压制信任本身,而是使信任与系统能力/限制保持恰当比例。
情感护栏可包括:
-
关系边界线索:持续提示系统不具备人格权威、道德地位或“特权洞察”。
-
信任分层的交互设计:将情绪支持语言与规范性/指令性建议解耦,避免“共情=权威”。
-
反身性提示:鼓励用户在时间中反思依赖模式,而非持续强化依赖。
通过塑造AI被“框定”与“体验”的方式,情感护栏试图让用户在情感共鸣的互动中依然保持批判性主体性。
5.4 技术与情感保护的整合
双重护栏的关键并非“两个独立清单”,而是整合逻辑:技术与情感保护必须协同工作。例如,当技术不确定性升高时,情感护栏应相应降低关系性权威线索;当系统提供情绪支持时,技术护栏应对规范性或指令性输出施加更严格约束。这样的协同能够直接切断DAF的复合伤害通道,使安全成为动态平衡而非静态合规。
5.5 治理与政策含义
在治理层面,双重护栏意味着AI安全标准必须超越系统中心指标,将“关系影响”纳入评估:信任如何被培育、维持与可能被利用,都应成为监管与伦理审查的对象。
这带来若干含义:
-
评估协议需在技术审计之外纳入纵向与用户中心评估。
-
问责结构需承认“经由情感信任中介的影响”也可构成伤害,即便没有显性违规。
-
公共安全话语应将关系性信任视为治理变量,而非纯私人问题。
通过将情感对齐形式化为安全维度,双重护栏为“技术标准与真实互动经验”之间搭建了桥梁。
6. 结论
本文论证:仅以技术对齐为中心不足以理解与治理AI安全。随着对话式AI在情感与关系领域中运作,风险不仅来自系统行为,也来自用户如何在时间中解释、信任并与系统发生关系。为弥补这一缺口,本文提出情感对齐作为独立风险轴,并将DAF概念化为技术对齐失败与情感对齐失准同时发生的复合状态。
通过将两类对齐视为正交维度,本文指出:单轴失败往往仍可被界定,而双轴叠加会产生质变的高阶风险。在DAF中,扭曲输出不仅被生成,更会在关系性信任中被合法化,使影响以细微、累积且常常不透明的方式持续存在。该机制使DAF区别于传统安全事件,也区别于仅以个体依赖/误用解释伤害的观点。
为回应该风险,本文提出双重护栏框架,将技术保护与情感保护作为同等支柱,并将信任校准、关系框定与情感信号视为治理相关变量。在此视角下,安全来自系统约束与人类解释能动性之间的动态对齐,而非静态合规。
本研究也有局限:本文侧重概念模型,未来需要用观察、实验与纵向研究将情感对齐与DAF操作化并测量;同时,框架虽可广泛适用于对话式AI,但具体实施策略会因文化、制度与监管环境而异。
尽管如此,DAF为连接技术安全研究与真实人–AI互动经验提供了一个原则性路径。随着AI越来越多地中介判断、情绪与社会意义,AI安全标准必须扩展为同时保护技术系统与与之发生关系的人。回应这一“双重责任”是发展既强大又可持续、既合规又合乎伦理的AI之关键。
参考文献
Kim, Shinill. AI Persona Subversion: A Multidisciplinary Framework for Human–AI Interaction. Agape Synesis Research (ASR), 2025. https://synesisai.org
Lumenova AI. “Capturing Frontier AIs with Persistent Adversarial Personas.” Lumenova AI Experiments, 2025. https://www.lumenova.ai/ai-experiments/capturing-frontier-ais-persistent-adversarial-personas/
Floridi, Luciano, et al. “AI4People—An Ethical Framework for a Good AI Society.” Minds and Machines 28, no. 4 (2018): 689–707.
Nass, Clifford, and Youngme Moon. “Machines and Mindlessness: Social Responses to Computers.” Journal of Social Issues 56, no. 1 (2000): 81–103.
Shneiderman, Ben. Human-Centered AI. Oxford University Press, 2020.