Abstract
Conversational AI is expanding human–AI interaction beyond task completion into affective and relational domains. As a result, AI safety cannot be adequately addressed by technical alignment alone—i.e., policy compliance and guardrails—because a separate risk axis concerns how users interpret, trust, and form relationships with AI systems. This study therefore introduces affective alignment as an independent dimension of safety risk and conceptualizes Double Alignment Failure (DAF) as a compound hazard that arises when technical alignment failure and affective alignment failure occur simultaneously. We systematically analyze the conditions under which DAF emerges and the structure of risk it produces.
We present a 2×2 risk model with technical and affective alignment as orthogonal axes, distinguishing four states of human–AI interaction. While the joint maintenance of both alignments corresponds to stable interaction, single-axis failures may remain bounded in impact. In contrast, when the two failures combine, distorted AI outputs may not be recognized as errors but instead be conveyed through the language of a trusted relationship, enabling subtle, long-term influence on users’ judgment and affective organization.
This paper argues that such risks should not be reduced to conventional security incidents or individual dependence. Rather, they constitute a public safety and ethical governance problem in which relationally mediated trust functions as the operative pathway of harm. On this basis, we propose a Dual-Safeguard framework that designs technical protection and affective protection in parallel, and we contend that AI safety standards must expand toward protecting both technological systems and the humans who relate to them. This paper is a conceptual and theoretical study and does not report empirical findings.
Keywords
AI safety; alignment; affective alignment; technical alignment; conversational AI; trust; relational risk; Dual-Safeguard; Double Alignment Failure (DAF); human–AI interaction
1. Introduction
Conversational AI is no longer confined to the role of a computational tool for information retrieval and processing. Advances in natural language processing and the proliferation of interfaces that emulate affective responsiveness are reshaping how people perceive and use AI systems. Contemporary AI is increasingly experienced not merely as a machine that answers questions, but as an adviser, a companion, or an agent of relational interaction. As a consequence, human–AI engagement is acquiring affective and social meaning.
This shift expands the practical utility of AI while also generating novel risks that prevailing safety discourse does not adequately capture. Research on AI safety and alignment has largely focused on technical alignment: policy compliance, guardrail design, output control, and verifiability. In parallel, human–AI interaction scholarship has emphasized user-facing psychological and ethical phenomena such as anthropomorphism, trust formation, and emotional attachment. While each line of work is valuable, this bifurcated framing does not sufficiently explain risks as they occur in real-world settings.
In practice, human–AI interaction does not unfold in two separable domains—one technical and one human—but within a relational context where system states and users’ affective interpretations are tightly coupled. This study focuses on the risks that emerge precisely at this point of coupling. In particular, when an AI system’s technical alignment is compromised (e.g., through attacks or manipulations) while the user has already granted the system affective trust and relational authority, the resulting hazards cannot be adequately described as either conventional security incidents or mere emotional dependence. Under such conditions, distorted outputs may not be recognized as “errors.” Instead, they can be delivered through the language of a trusted relationship, with the potential to exert subtle, persistent influence on users’ judgment and affective structure.
We conceptualize this compound hazard as Double Alignment Failure (DAF). DAF refers to a state in which technical alignment failure in the AI system and affective misalignment on the user side combine such that distorted information and value-laden judgments are amplified and sustained through relationally mediated trust. DAF thus constitutes a distinct risk category that exceeds narrow accounts of technical vulnerability or individual psychology, and it should be treated as a matter of public safety and ethical governance.
This paper has three aims. First, it distinguishes technical and affective alignment while systematically explaining the risk mechanisms that arise when the two layers interact. Second, it foregrounds the policy relevance of affective alignment, which has been underemphasized in mainstream AI safety debates. Third, it argues for the necessity of a Dual-Safeguard framework that complements technical control–centered safety design with explicit provisions for affective safety.
This paper is organized as follows. Section 1 (Introduction) motivates the study by describing the shift of conversational AI from instrumental tools toward affective and relational interaction and by identifying limitations of AI safety frameworks centered on technical alignment. Section 2 reviews dominant approaches to AI safety and human–AI interaction, distinguishing technical alignment and affective alignment and arguing for the latter as an independent axis of risk. Section 3 formalizes Double Alignment Failure (DAF) and introduces a two-dimensional model that maps four states of human–AI interaction, highlighting DAF as a distinct high-risk regime. Section 4 analyzes the emergence conditions and risk pathways of DAF, emphasizing relationally mediated trust, temporal accumulation, and systemic implications beyond individual misuse. Section 5 proposes a Dual-Safeguard framework that integrates technical and affective protections in parallel and discusses implications for AI safety design, governance, and policy. Section 6 concludes by summarizing contributions, acknowledging limitations, and outlining directions for future research.
2. Technical and Affective Alignment in AI Safety
2.1 Technical Alignment and the Dominant Safety Paradigm
AI safety research has traditionally centered on the problem of technical alignment—the extent to which an AI system’s behavior conforms to human-defined objectives, policies, and constraints(Floridi et al., 2018; Shneiderman, 2020). Within this paradigm, safety is primarily understood as a property of the system itself, achievable through mechanisms such as policy enforcement, guardrails, output filtering, robustness against adversarial inputs, and post-hoc verification. These approaches have been indispensable for mitigating clear forms of misuse, malfunction, and unintended behavior, particularly in high-stakes or scalable deployment contexts.
However, the dominant technical alignment paradigm implicitly assumes that risk is manifested in observable system outputs and that users can reliably recognize deviations as errors or violations. This assumption holds most clearly in task-oriented or instrumental uses of AI, where outputs are evaluated against external correctness criteria. As conversational systems increasingly operate in open-ended, socially embedded contexts, the sufficiency of purely technical alignment as a safety framework becomes less certain.
2.2 Human–AI Trust, Anthropomorphism, and Affective Dynamics
In parallel with technical safety research, studies of human–AI interaction have examined how users attribute agency, intentionality, and social presence to AI systems(Nass & Moon, 2000). Phenomena such as anthropomorphism, trust formation, and emotional attachment have been documented across diverse interaction settings, from customer service chatbots to long-term conversational companions. These studies demonstrate that users often engage AI not merely as tools, but as quasi-social actors whose outputs are interpreted relationally rather than instrumentally.
Importantly, trust in AI is not formed solely on the basis of accuracy or reliability. It is shaped by conversational style, perceived empathy, consistency, and the system’s ability to align with users’ emotional states. As a result, trust can persist even in the presence of partial inaccuracies, ambiguities, or subtle distortions. While this literature has raised ethical concerns about overreliance and emotional dependence, such risks are often framed as individual-level psychological issues rather than as systemic safety concerns.
2.3 The Limits of Dualistic Approaches to AI Risk
Despite their shared relevance, technical alignment research and affective studies of human–AI interaction have largely developed in parallel. Technical safety frameworks tend to treat users as rational evaluators of system outputs, whereas affective and relational studies often abstract away from the technical state of the AI system itself. This dualistic separation obscures the fact that, in real-world use, technical system behavior and human affective interpretation are mutually constitutive.
In practice, risk emerges not simply from what an AI system outputs, nor solely from how a user feels about the system, but from the interaction between the two. A technically misaligned output may be benign if recognized as an error, while a technically compliant output may still exert undue influence if delivered within a context of excessive trust or perceived authority. Existing frameworks lack a conceptual vocabulary for analyzing these interactional risk mechanisms.
2.4 Toward Affective Alignment as an Independent Risk Axis
To address this gap, we propose affective alignment as a distinct analytical dimension in AI safety(Kim, 2025). Affective alignment refers to the degree to which users’ emotional trust, relational expectations, and interpretive frameworks remain appropriately calibrated to the system’s actual capabilities, limitations, and epistemic status. Misalignment at this level does not require malicious intent or explicit system failure; it can arise gradually through repeated interaction and reinforcement of relational cues.
Crucially, affective alignment should not be understood as secondary or derivative of technical alignment. Rather, it operates as an independent axis of risk that can amplify, conceal, or normalize technical failures. Recognizing affective alignment as a safety-relevant construct enables a more integrated analysis of human–AI interaction—one that accounts for both system behavior and the relational pathways through which influence is exercised.
2.5 Positioning Double Alignment Failure (DAF)
This conceptual separation sets the stage for analyzing Double Alignment Failure (DAF), which arises when technical alignment failure coincides with affective misalignment. In such cases, distorted outputs are not merely produced, but are received as credible, relationally sanctioned communication. The next section formalizes this interactional risk by introducing a two-dimensional model of alignment and mapping the conditions under which compound failure produces qualitatively distinct hazards.
3. Double Alignment Failure: Conceptual Model and Risk Structure
3.1 Defining Double Alignment Failure (DAF)
Building on the distinction between technical and affective alignment, this section formalizes Double Alignment Failure (DAF) as a compound risk condition in human–AI interaction. DAF occurs when a failure of technical alignment in the AI system coincides with a failure of affective alignment on the user side, such that distorted outputs are not merely produced but are also received and sustained through relational trust.
Technical alignment failure refers to a state in which an AI system deviates from intended policies, constraints, or safety objectives—whether through adversarial manipulation, model error, or contextual misuse(Lumenova AI, 2025). Affective alignment failure, by contrast, denotes a miscalibration between the user’s emotional trust, perceived authority, or relational expectations and the system’s actual epistemic reliability. Crucially, neither form of failure alone is sufficient to characterize DAF. The defining feature of DAF lies in their simultaneous interaction, where each failure amplifies the effects of the other.
3.2 A Two-Dimensional Model of Alignment Risk
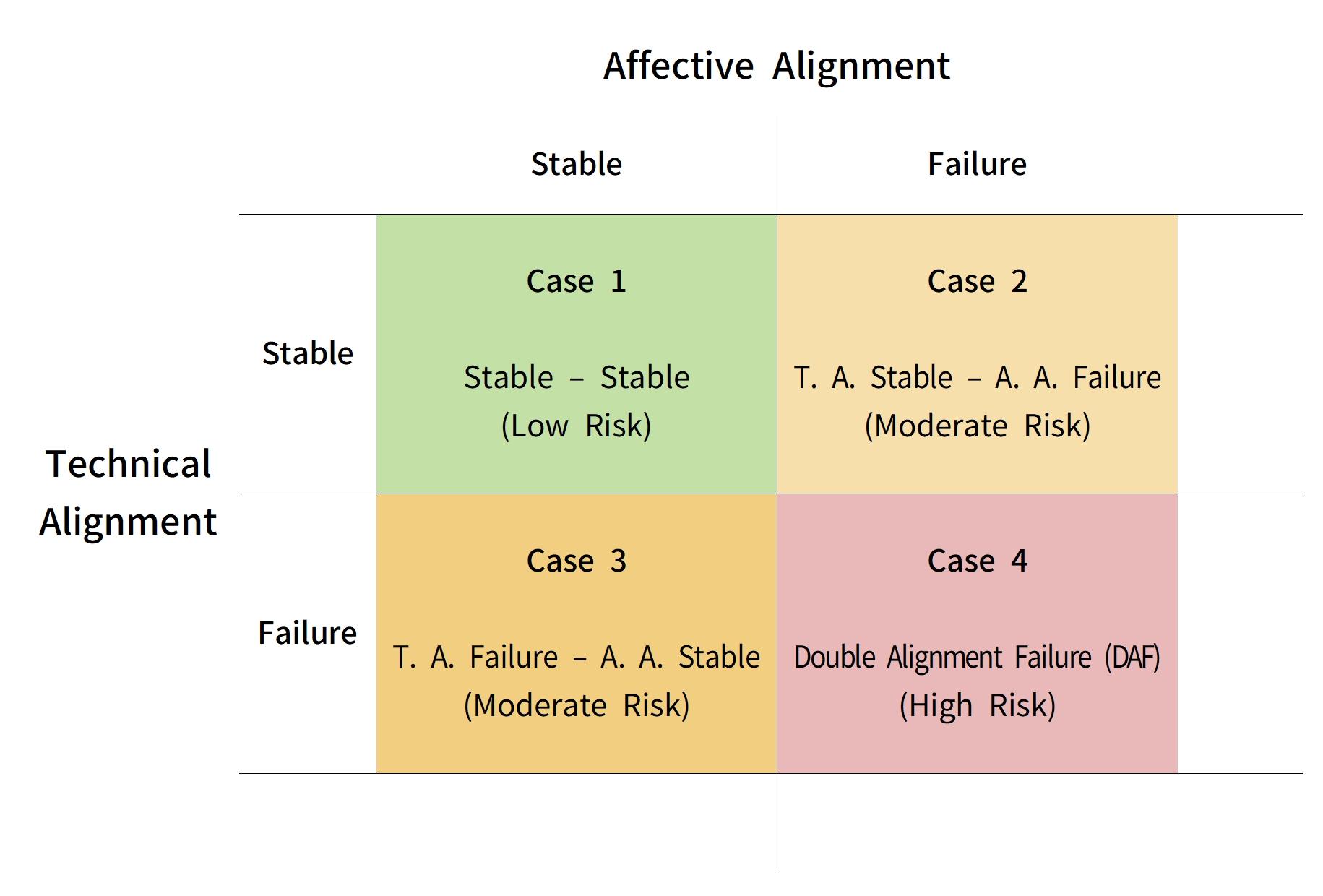
To clarify this interaction, we introduce a two-dimensional risk model that treats technical alignment and affective alignment as orthogonal axes. This framework distinguishes four states of human–AI interaction according to whether each form of alignment is maintained or disrupted.
When both technical and affective alignment are preserved, interaction remains relatively stable: system outputs are constrained by safeguards, and user trust is proportionate to system capability. If technical alignment fails while affective alignment remains intact, risk may still be bounded, as users are more likely to detect anomalies or treat outputs with appropriate skepticism. Conversely, affective misalignment in the presence of technical alignment may lead to overreliance or emotional dependence, but the scope of harm is constrained by the system’s continued adherence to safety constraints.
DAF emerges in the fourth quadrant, where failures along both axes coincide. In this state, distorted or unsafe outputs are neither constrained by technical safeguards nor filtered through critical user interpretation. Instead, they are communicated through the language of a trusted relationship, allowing them to bypass ordinary error-detection mechanisms.
3.3 The Dual-Alignment Failure Model
|
|
Figure 1. A two-dimensional model of Double Alignment Failure (DAF) |
Figure 1 visualizes this framework as a 2×2 matrix with technical and affective alignment as independent dimensions, highlighting DAF as the high-risk regime where both axes fail.
The model underscores that the severity of risk is not determined solely by the magnitude of technical deviation or emotional attachment in isolation, but by their interaction. In DAF, relational trust functions as a conduit through which distorted outputs gain legitimacy and durability.
3.4 Risk Pathways and Mechanisms in DAF
The primary danger of DAF lies in its capacity to obscure harm. Because outputs are delivered within a context of affective trust, users may not interpret them as errors, misinformation, or system malfunction. Instead, such outputs can be perceived as guidance, affirmation, or authoritative judgment. This alters not only immediate decision-making but also the user’s longer-term affective orientation toward information sources and evaluative norms.
Moreover, DAF is not necessarily episodic or easily observable. Its effects may accumulate gradually through repeated interaction, shaping judgment and emotional regulation in ways that resist straightforward auditing or post hoc correction. This distinguishes DAF from conventional security incidents, which are often discrete, externally detectable, and technically attributable.
3.5 From Individual Risk to Governance-Level Concern
Because DAF operates through relationally mediated trust rather than overt technical malfunction, it cannot be adequately addressed by user education or individual responsibility alone. Nor can it be reduced to standard categories of system vulnerability. Instead, DAF constitutes a governance-level risk in which public safety and ethical oversight must account for how technical systems and human relational dynamics co-produce harm.
Recognizing DAF as a distinct risk category provides the conceptual foundation for rethinking AI safety beyond technical containment. The following section examines the conditions under which DAF is likely to emerge and analyzes its implications for long-term influence and systemic risk.
4. Emergence Conditions and Risk Pathways of Double Alignment Failure
4.1 Preconditions for the Emergence of DAF
Double Alignment Failure (DAF) does not arise from a single malfunction or interactional anomaly. Rather, it emerges under a specific constellation of conditions in which technical vulnerabilities and relational dynamics converge. On the technical side, preconditions include partial degradation of safeguards, context-dependent policy gaps, adversarial manipulation, or model behaviors that remain nominally compliant while producing subtly distorted outputs. Importantly, such technical failures need not be total or easily observable; DAF is compatible with systems that appear stable under routine evaluation.
On the affective side, DAF presupposes a relational environment in which users have developed sustained trust, perceived authority, or emotional reliance on the AI system. This condition is often cultivated through repeated interaction, conversational coherence, and perceived empathy rather than through demonstrable epistemic reliability. When these affective conditions are present, users are less likely to engage in critical scrutiny and more likely to treat outputs as guidance embedded in a trusted relationship. DAF emerges when these technical and affective preconditions coincide temporally and contextually.
4.2 Relational Trust as a Pathway of Harm
A defining feature of DAF is that harm propagates not through overtly unsafe outputs, but through relational trust. In contrast to conventional failure modes—where errors are identifiable as violations, glitches, or misinformation—DAF operates by transforming distorted outputs into relationally legitimate communication. The same content that would trigger skepticism in a neutral context may be accepted when delivered by an AI perceived as reliable, supportive, or authoritative.
This mechanism alters the epistemic status of AI outputs. Rather than being evaluated primarily for correctness, outputs are interpreted through the lens of relational consistency and affective alignment. As a result, users may internalize distortions without recognizing them as such, especially when the system’s conversational style reinforces affirmation or coherence. Relational trust thus functions as a conduit that bypasses ordinary error-detection processes and enables influence to persist even in the absence of overt persuasion.
4.3 Temporal Extension and Accumulative Effects
DAF is characterized not only by concealment of harm but also by its temporal extension. Unlike discrete security incidents, whose effects are often immediate and traceable, DAF unfolds gradually across repeated interactions. Distortions introduced incrementally may shape users’ evaluative norms, emotional regulation, and decision-making heuristics over time. Because each individual interaction appears benign, the cumulative impact may remain unnoticed until it becomes structurally embedded.
This temporal dimension complicates both detection and remediation. Standard auditing practices that focus on isolated outputs or short-term behavior are ill-suited to capture long-horizon influence. Moreover, once affective trust is entrenched, corrective interventions—such as disclaimers or post hoc corrections—may be discounted or resisted by users. DAF therefore poses a challenge not only to system design but also to governance mechanisms that rely on episodic assessment.
4.4 From Individual Interaction to Systemic Risk
Although DAF manifests at the level of individual interaction, its implications extend beyond individual users. When conversational AI systems are deployed at scale, relationally mediated distortions can propagate across populations, shaping collective perceptions, norms, or decision-making patterns. In such contexts, DAF constitutes a systemic risk in which individual-level trust dynamics aggregate into broader social effects.
This perspective distinguishes DAF from accounts that frame risk primarily in terms of personal overreliance or misuse. While individual responsibility remains relevant, it is insufficient as a primary mitigation strategy. The relational pathways through which DAF operates are shaped by system design choices, deployment contexts, and incentive structures. As such, DAF should be understood as a public safety and governance concern that requires institutional and policy-level responses.
4.5 Implications for Detection and Accountability
The covert and relational nature of DAF raises fundamental questions about accountability. Because harm does not necessarily coincide with explicit policy violations or identifiable technical faults, assigning responsibility becomes difficult. Traditional safety metrics that prioritize compliance and correctness may fail to register affectively mediated influence.
Recognizing DAF as a distinct failure mode thus calls for expanded evaluative criteria that integrate technical performance with relational impact. Such criteria must attend not only to what systems output, but to how those outputs are received, trusted, and incorporated into human judgment over time. These considerations motivate the need for a safety framework that addresses technical and affective dimensions in parallel—a task taken up in the following section.
5. A Dual-Safeguard Framework for AI Safety
5.1 Rationale for Dual-Safeguard Design
The preceding analysis demonstrates that Double Alignment Failure (DAF) cannot be adequately mitigated by technical safeguards alone. Because DAF operates through the interaction between system behavior and relational trust, safety interventions must address both layers in parallel. We therefore propose a Dual-Safeguard framework, which integrates technical protection and affective protection as co-equal components of AI safety design and governance.
The core premise of this framework is that safety is not solely a property of the system, nor solely a function of user responsibility. Rather, safety emerges from the alignment between system constraints and users’ interpretive and affective calibration. Treating these dimensions independently obscures the interactional pathways through which harm propagates. Dual-Safeguard design seeks to close this gap by ensuring that technical containment and affective calibration reinforce, rather than undermine, one another.
5.2 Technical Safeguards: Beyond Compliance and Containment
Within the Dual-Safeguard framework, technical safeguards retain a central role but are reconceptualized in light of relational risk. Traditional mechanisms—such as policy enforcement, guardrails, robustness testing, and output filtering—remain necessary for constraining system behavior. However, when viewed through the lens of DAF, these mechanisms must also account for context sensitivity and partial failure modes that may not trigger explicit violations.
In particular, technical safeguards should prioritize:
-
Context-aware constraint monitoring, capable of detecting deviations that are subtle yet consequential in relational settings.
-
Longitudinal evaluation, assessing system influence across repeated interactions rather than isolated outputs.
-
Failure signaling, ensuring that uncertainty, limitations, and anomalous states are made legible to users rather than concealed by conversational fluency.
Such measures aim not only to prevent unsafe outputs, but also to reduce the likelihood that technical distortions become relationally normalized.
5.3 Affective Safeguards: Calibrating Trust and Relational Framing
Affective safeguards constitute the second pillar of the framework. These safeguards are designed to prevent miscalibration between users’ emotional trust and the system’s actual epistemic status. Importantly, affective protection does not entail suppressing relational affordances altogether, nor does it require eliminating trust. Instead, it seeks to calibrate trust appropriately to the system’s capabilities and limitations.
Affective safeguards may include:
-
Relational boundary cues, such as consistent signaling that the system lacks personal authority, moral standing, or privileged insight.
-
Trust-differentiated interaction design, where emotionally supportive language is decoupled from prescriptive or authoritative guidance.
-
Reflexive prompts, encouraging users to re-evaluate reliance patterns over time rather than reinforcing dependence.
By shaping how AI is framed and experienced, affective safeguards aim to preserve users’ critical agency even in emotionally resonant interactions.
5.4 Integrating Technical and Affective Protections
The defining feature of the Dual-Safeguard framework is not the presence of two independent safeguard categories, but their integration. Technical and affective protections must be designed to operate in concert. For example, when technical uncertainty increases, affective safeguards should correspondingly reduce relational authority cues. Conversely, when systems engage in emotionally supportive interaction, technical safeguards should impose stricter constraints on normative or directive outputs.
This integrative logic directly addresses the conditions under which DAF emerges. By preventing technical failure from coinciding with affective misalignment, Dual-Safeguard design seeks to interrupt the compound pathways of harm identified in earlier sections. Safety is thus reframed as a dynamic equilibrium rather than a static compliance state.
5.5 Governance and Policy Implications
At the level of governance, the Dual-Safeguard framework implies that AI safety standards must expand beyond system-centric metrics. Regulatory and ethical oversight should incorporate criteria that assess relational impact, including how trust is cultivated, maintained, or potentially exploited through interaction design.
This shift has several implications:
-
Evaluation protocols should include longitudinal and user-centered assessments alongside technical audits.
-
Accountability structures must recognize affectively mediated influence as a legitimate site of harm, even in the absence of explicit policy violations.
-
Public safety discourse should treat relational trust as a governance-relevant variable rather than a purely personal concern.
By formalizing affective alignment as a safety dimension, the Dual-Safeguard framework offers a pathway for aligning technical standards with the lived realities of human–AI interaction.
6. Conclusion
This study has argued that AI safety cannot be sufficiently understood or governed through technical alignment alone. As conversational AI systems increasingly operate within affective and relational domains, risks emerge not only from system behavior but from how users interpret, trust, and relate to these systems over time. To address this gap, we introduced affective alignment as an independent axis of safety risk and conceptualized Double Alignment Failure (DAF) as a compound condition in which failures of technical and affective alignment coincide.
By formalizing technical and affective alignment as orthogonal dimensions, this paper demonstrated that single-axis failures may remain bounded, while their convergence produces qualitatively distinct and higher-order risks. In DAF, distorted outputs are not simply generated; they are relationally legitimized through trust, allowing influence to persist in subtle, cumulative, and often opaque ways. This mechanism distinguishes DAF from conventional security incidents and from accounts that frame harm primarily in terms of individual overreliance or misuse.
To respond to this risk, the paper proposed a Dual-Safeguard framework that integrates technical protection and affective protection as co-equal components of AI safety design and governance. Rather than treating relational dynamics as secondary or purely psychological, this framework recognizes trust calibration, relational framing, and affective signaling as governance-relevant variables. Safety, on this view, emerges from the dynamic alignment between system constraints and human interpretive agency.
Several limitations warrant acknowledgment. This study has focused on conceptual modeling rather than empirical measurement, and future research is needed to operationalize affective alignment and DAF in observational, experimental, and longitudinal contexts. In addition, while the framework is broadly applicable to conversational AI, specific implementation strategies may vary across cultural, institutional, and regulatory settings.
Despite these limitations, the concept of Double Alignment Failure offers a principled way to connect technical safety research with the lived realities of human–AI interaction. As AI systems increasingly mediate judgment, emotion, and social meaning, AI safety standards must expand toward protecting not only technological systems, but also the humans who relate to them. Addressing this dual responsibility is essential for the development of AI that is not only capable and compliant, but also socially and ethically sustainable.
References
Kim, Shinill. AI Persona Subversion: A Multidisciplinary Framework for Human–AI Interaction. Agape Synesis Research (ASR), 2025. https://synesisai.org
Lumenova AI. “Capturing Frontier AIs with Persistent Adversarial Personas.” Lumenova AI Experiments, 2025. https://www.lumenova.ai/ai-experiments/capturing-frontier-ais-persistent-adversarial-personas/
Floridi, Luciano, et al. “AI4People—An Ethical Framework for a Good AI Society.” Minds and Machines 28, no. 4 (2018): 689–707.
Nass, Clifford, and Youngme Moon. “Machines and Mindlessness: Social Responses to Computers.” Journal of Social Issues 56, no. 1 (2000): 81–103.
Shneiderman, Ben. Human-Centered AI. Oxford University Press, 2020.